尚書七號OCR免費版
下載地址
下載地址

尚書七號OCR免費版是一款提供了多種圖片以及文字識別功能的軟件,軟件支持對多種圖片文字進行精準的提取,同時支持對提取后的內容進行編輯,編輯完成之后支持多種輸出格式,一鍵選擇更加便捷,通過對各種紙質文檔進行掃描一鍵獲取電子文檔。
1.從本站下載后解壓,雙擊Setup.exe開始安裝。
2.點擊下一步。
3.修改安裝地址,點擊下一步。
4.安裝中。
5.安裝完成,從開始菜單啟動尚書七號OCR。
1.識別字符:簡體字符集:國標GB2312-80的全部一、二級漢字6800多個。純英文字符集。 簡繁字集:除了簡體漢字外,還可以混識臺灣繁體字5400多個以及香港繁體字和GBK漢字。
2.識別字體種類:能識別宋體、仿宋、楷、黑、魏碑、隸書、圓體、行楷等一百多種字體,并支持多種字體混排。
3.識別字號:初號 小六號字體。
4.表格識別:可以自動判斷、拆分、識別和還原各種通用型印刷體表格。
5.尚書七號ocr可支持繁體WINDOWS系統
用尚書七號對文字圖像識別轉化的過程,利用其主菜單:“文件”、“編輯”、“識別”、“輸出”可以很方便地完成。
具體步驟
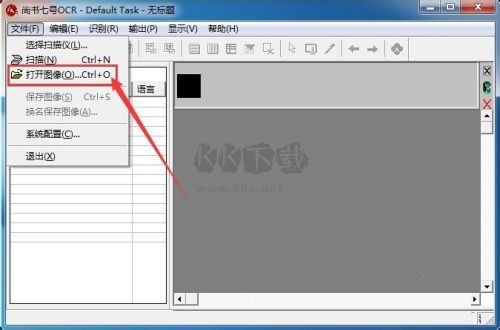
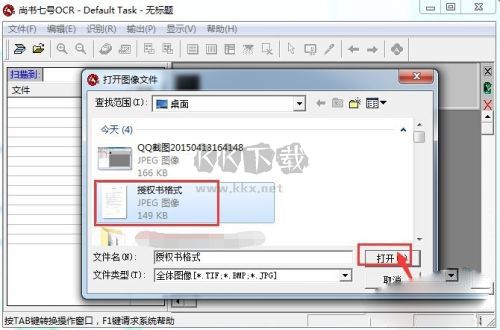
1.獲取文字圖像文件
選擇“文件”菜單下的“掃描”或“打開圖像”(將已經掃描好的圖像文件打開)命令,打開圖像文件。如果連接了多臺掃描儀,可以選擇“文件”菜單下的“選擇掃描儀”命令,調用掃描儀。
2.對掃描的圖像頁進行調整
選擇“編輯”菜單下“圖像頁面的處理”子菜單下的“圖像頁的傾斜校正”(提供自動和手動實現方法)及“旋轉”等命令,將掃描的圖像頁進行調整。
3.版面分析與文字識別轉化
版面分析,選擇識別范圍,在進行文字識別前要選擇識別范圍,識別過程的核心是“版面分析”。
尚書七號的自動版面分析功能很強,對報紙雜志等復雜的版面,也能保持很高的分析正確率。
設置好后,直接點擊“開始識別”的按鈕就可以進行文字識別了。
4.校對修改
自動識別完畢,識別結果的“文本窗口”會彈出,這個窗口能夠提供識別結果的校對,為了校對方便,尚書七號增加了光標跟隨顯示原圖像行的校對方法。
提供的校對方法,一眼就能夠看到圖像原文和識別出文本的差別,如果發現識別有誤,可以進行修改。
5.輸出
如果檢查修改后確認無誤,選擇識別結果的“輸出”菜單,輸出的文件格式有:RTF、HTML、XLS、22238,可以根據自己的需要選擇對應的格式。
如果用戶想得到類似原文的識別結果,請選擇RTF格式。把RTF格式輸出的文件用WORD打開后,會發現幾乎保留了原文的所有痕跡,包括原來頁面中的彩色圖像,都已經保留在WORD中了。
尚書七號OCR免費版 v7.544.42M返回頂部
Copyright © 2009-2023 KKX.Net. All Rights Reserved .
KK下載站是專業的免費軟件下載站點,提供綠色軟件、免費軟件,手機軟件,系統軟件,單機游戲等熱門資源安全下載!
本站資源均收集整理于互聯網,其著作權歸原作者所有,如果有侵犯您權利的資源,請來信告知


 字體管家 v5.7 官方最新版
字體管家 v5.7 官方最新版 電子日記本eDiary v5.0免費版
電子日記本eDiary v5.0免費版 樹洞OCR文字識別 v1.5綠色免費版
樹洞OCR文字識別 v1.5綠色免費版 SJQY字體下載電腦版
SJQY字體下載電腦版  PDF OCR v4.7.2 綠色免費版
PDF OCR v4.7.2 綠色免費版 dnGrep文件搜索助手 v4.0.151 綠色版
dnGrep文件搜索助手 v4.0.151 綠色版 好用便簽官網版 V5.1.2正版
好用便簽官網版 V5.1.2正版