Zookeeper主要是由一些名為“znode”的數據對象來存儲數據。 這些znode可以形成樹形目錄結構(也就是所謂的“zookeeper樹”),客戶端應用程序可以在此樹中讀寫數據。 Zookeeper還具有多種特性來保證數據的一致性和正確性:例如原子性、順序保證、通告/通告機制、崩潰時采取必要步驟以避免不合理行為、監聽/監聽者事件處理機制以及快速失敗重新嘗試。
因此,Zookeeper在大型分布式集群中是不可或缺的一部分:實時數據共享、集體決斷、已注冊服務注冊表、命否協作/眾包協作、加密/安全憑證存儲和使用者會話/上下文存儲都需要Zookeeper作為能夠承載這些功能的平臺。
zookeeper安裝配置
1、下載完畢解壓縮放到C盤。
2、然后進入conf文件夾。
3、右鍵“zoo_sample.cfg”,然后選擇用記事本打開。
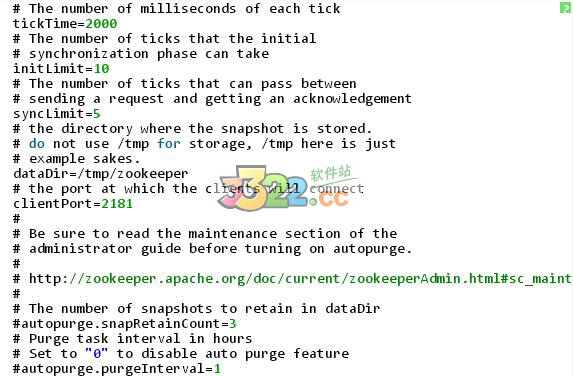
4、在conf文件夾中新建名為“zoo.cfg”的文件(ZooKeeper在啟動時會找名為“zoo.cfg”的文件并將其作為默認配置文件),并用記事本打開,將原來名為“zoo_sample.cfg”的文件中的內容拷貝到新建的“zoo.cfg”文件中并進行必要的修改,如:
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
# initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
# syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=C:/zookeeper-3.4.5/data
# the port at which the clients will connect
clientPort=2181
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
至此ZooKeeper在Windows操作系統中安裝配置完畢,但需要指出的是ZooKeeper是使用Java編寫的,因此運行ZooKeeper之前必須安裝Java環境——配置JDK,且JDK的版本要大于或等于1.6。
zookeeper使用說明
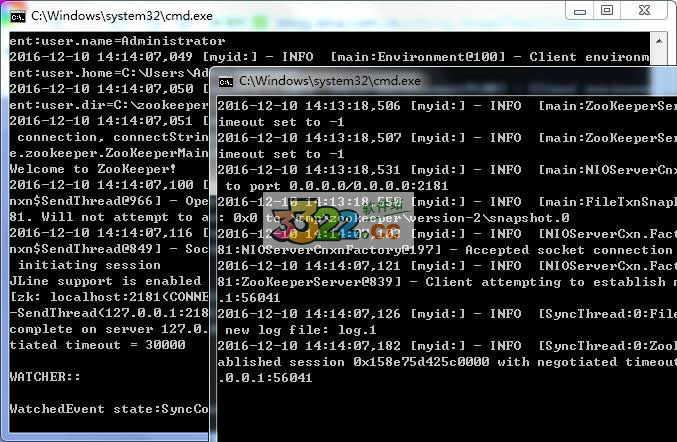
1、打開bin文件夾,找到其中的的“zkServer.cmd”和“zkCli.cmd”,然后運行,下面的.sh文件是給Linux系統的用戶準備的。這里需要注意,先啟動“zkServer.cmd”服務端,再啟動“zkCli.cmd”客戶端就OK了
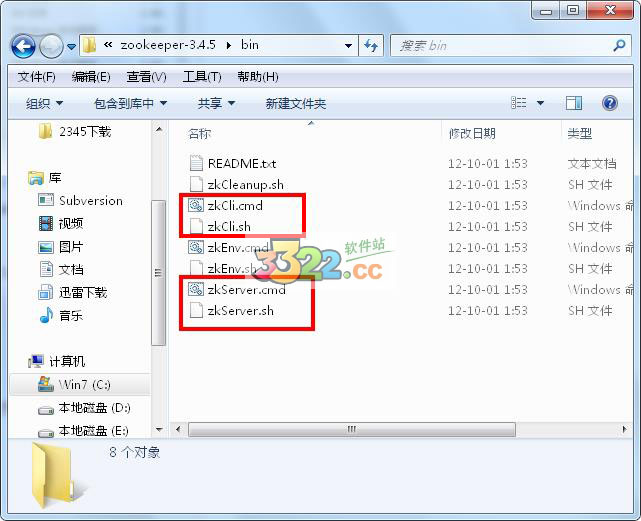
最后,需要注意不要關閉這兩個cmd窗口。
Zookeeper原理
1、選舉Leader。
2、同步數據。
3、選舉Leader過程中算法有很多,但要達到的選舉標準是一致的。
4、Leader要具有最高的zxid。
5、集群中大多數的機器得到響應并follow選出的Leader。
Zookeeper特點
在Zookeeper中,znode是一個跟Unix文件目錄途徑相近的節點,能夠往這一節點存放或讀取數據。假如在創建znode時Flag設為EPHEMERAL,因此當建立這一znode的節點和Zookeeper喪失聯接后,這一znode將不再存在在Zookeeper里,Zookeeper應用Watcher發覺事情信息。當手機客戶端接受到事情信息,例如網絡連接超時、節點數據信息更改、子節點更改,能夠啟用對應的個人行為來建立模型。Zookeeper的Wiki頁面展示了怎么使用Zookeeper來處理程序通告,序列,堆排序,鎖,共享鎖,可撤銷的共享鎖,兩階段提交。
那樣Zookeeper能做什么事呢,典型的例子:假定我們會有20個搜索引擎的服務器(每一個承擔總索引中的一部分的搜索任務)和一個總服務器(承擔向這20個搜索引擎的服務器傳出檢索要求并合拼結果集),一個備用總服務器(承擔當總服務器崩潰時更換總服務器),一個web的cgi(向總服務器傳出檢索要求)。搜索引擎的服務器里的15個服務器提供搜索服務,5個服務器已經形成檢索。這20個搜索引擎的服務器常常想讓已經提供搜索服務的服務器終止提供服務項目逐漸形成檢索,或形成檢索的服務器已經將檢索形成進行能夠提供搜索服務了。應用Zookeeper可以確保總服務器全自動認知有多少個提供搜索引擎的服務器同時向這種服務器傳出檢索要求,當總服務器崩潰時自動開啟備用總服務器。
以上便是zookeeper客戶端!


 賤人工具箱 V5.8完全破解版
賤人工具箱 V5.8完全破解版 EduBoard電子白板系統 v8.0.0.0破解版
EduBoard電子白板系統 v8.0.0.0破解版 AutoRuns啟動項管理軟件 v13.97.0.0 綠色免安裝版
AutoRuns啟動項管理軟件 v13.97.0.0 綠色免安裝版 office2013激活工具 綠色免安裝版
office2013激活工具 綠色免安裝版 MikTeX v21.8 綠色免費版
MikTeX v21.8 綠色免費版 Screen+最新版 v1.4.2
Screen+最新版 v1.4.2 HttpWatch Pro v13.0.17中文版
HttpWatch Pro v13.0.17中文版 暢想之星閱讀器 v6.0官方版
暢想之星閱讀器 v6.0官方版